Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
Abstract
In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
Render and Diffuse
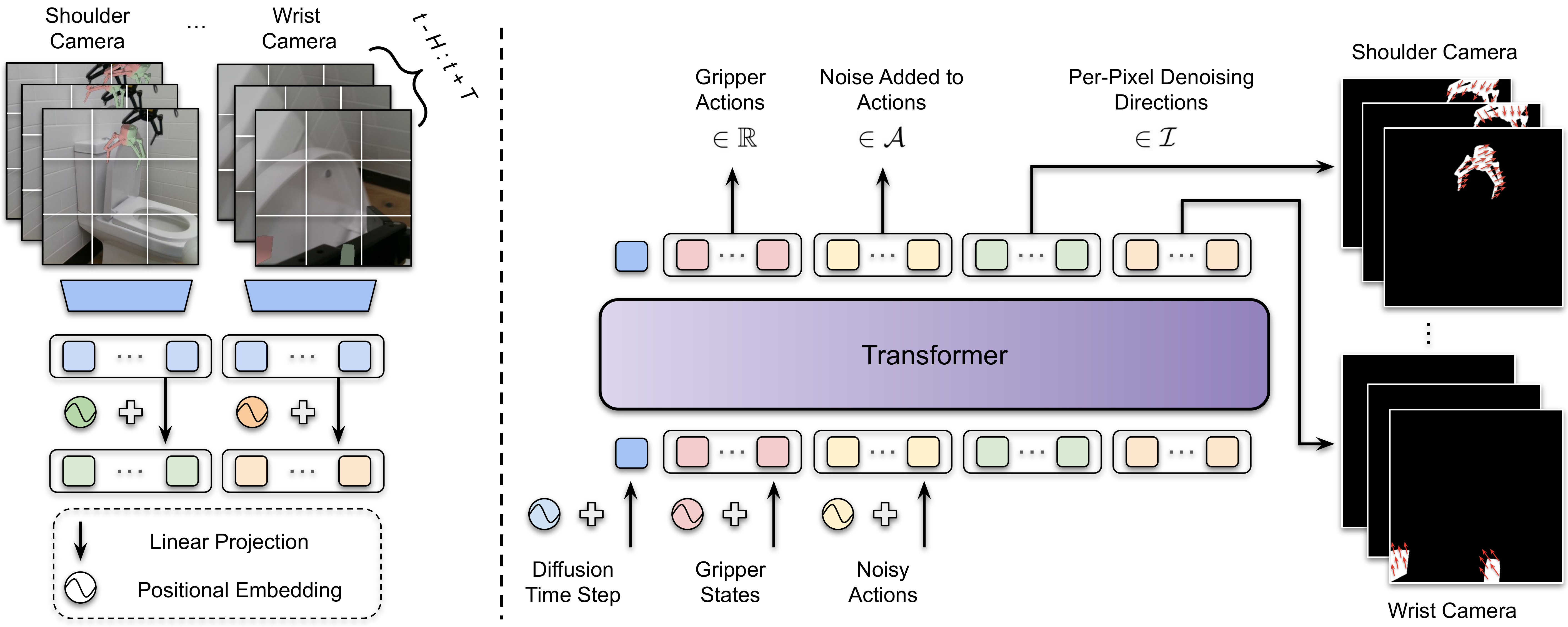
Overview of Render and Diffuse (R&D). We introduce a strategy that unifies image and action domains within a single image space (I), simplifying the learning process by reducing the complexity of navigating between these different spaces. This approach uses a rendering procedure and a known model of the robot to visually 'imagine' the spatial implications of the robot's actions. Through a learned denoising process, these rendered actions are updated until they closely align with the actions observed during the demonstrations. The architecture employs a Transformer model, where different positional embeddings are added to the tokenized input. These token embeddings are processed with several self-attention layers and then decoded into per-camera denoising directions in the image space, gripper actions, and noise added to the ground truth actions in the action space.
Robot Videos
Videos are captured from an external camera showing the robot performing everyday tasks at 2x speed.
Videos are composed of the actual images that the robot sees during the execution of the
tasks and our devised rendered action representation.
Observations from the shoulder and wrist cameras are shown on the left and right sides of each video,
respectively.
Different colours of the rendered grippers represent different action predictions in the future.